

O algoritmo Naive Bayes é um dos classificadores probabilísticos mais populares e eficientes em machine learning. Baseado no Teorema de Bayes, é um método robusto que se destaca pela sua simplicidade e pode ser aplicado em tarefas de classificação, como filtragem de spam, análise de sentimentos e reconhecimento de padrões.
Então, se você precisa de eficácia e rapidez para lidar com grandes volumes de dados, o Naive Bayes pode ser uma escolha interessante. Quer saber mais sobre esse algoritmo e
suas aplicações em machine learning?
Neste artigo, você conhecerá em detalhes o algoritmo Naive Bayes, desde seus fundamentos teóricos até suas aplicações práticas. Veja também as principais vantagens e desvantagens do Naive Bayes, saiba quando escolhê-lo em vez de outras abordagens, como avaliar o desempenho do modelo e tudo que você precisa saber para aprimorar seu conhecimento e aplicá-lo em projetos do mundo real. Vamos lá?
O que é o algoritmo Naive Bayes?
O algoritmo Naive Bayes é um classificador probabilístico amplamente utilizado em aprendizado de máquina, baseado no Teorema de Bayes. O teorema foi formulado pelo estatístico Thomas Bayes no século XVIII e permite calcular a probabilidade de um evento com base em informações anteriores. O Naive Bayes é caracterizado por sua simplicidade e eficiência, sendo uma escolha muito comum para tarefas de classificação, especialmente em contextos como filtragem de spam e análise de sentimentos.
O Naive Bayes se baseia no Teorema de Bayes, que pode ser expresso pela fórmula:
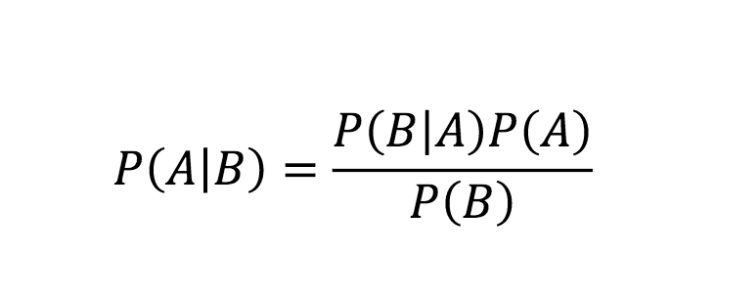
onde é a probabilidade posterior, P(B∣A) é a probabilidade verossímil, P(A) é a probabilidade anterior e P(B) é a evidência. O termo “naive” refere-se à suposição de que todas as características (atributos) são independentes entre si, dado o valor da classe, o que raramente é verdade na prática, mas simplifica os cálculos e permite que o algoritmo funcione de maneira eficiente.
Por que o Naive Bayes é importante?
O Naive Bayes costuma ser útil várias aplicações de machine learning por conta da sua capacidade de lidar com grandes volumes de dados, além da sua eficácia em problemas de classificação.
Aplicações práticas do Naive Bayes
Você pode ver o Naive Bayes sendo utilizado frequentemente em:
- classificação de e-mails para detectar spam, baseando-se em palavras e frases presentes no texto;
- análise de sentimentos para classificar opiniões em textos, utilizando palavras-chave para determinar a polaridade do texto;
- reconhecimento de padrões em tarefas como reconhecimento de fala e visão computacional, onde as características podem ser extraídas de imagens ou sinais de áudio;
- detecção de fraudes em sistemas financeiros, analisando padrões de transações.
Como funciona o algoritmo Naive Bayes?
O Teorema de Bayes fornece um método para atualizar a probabilidade de uma hipótese à medida que mais evidências se tornam disponíveis. Ele permite que o Naive Bayes faça previsões baseadas em dados observados.
O que significa “Naive”?
A suposição de independência condicional entre os atributos é o que torna o algoritmo “naive”. Isso significa que cada característica é independente das outras, o que simplifica o modelo, mas pode levar a erros em situações onde as características estão correlacionadas.
Descrição matemática simples do algoritmo
A probabilidade de uma classe C dada um conjunto de características X é calculada como:
P(C∣X)∝P(C)⋅P(X∣C)
onde P(X∣C) é a probabilidade de observar as características X dado que a classe é C.
Exemplos intuitivos
Um exemplo clássico é a classificação de frutas. Para determinar se uma fruta é uma maçã, o Naive Bayes considera características como cor, forma e tamanho de forma independente, calculando a probabilidade de cada uma contribuir para a classe “maçã”.
Tipos de algoritmos Naive Bayes
- Gaussian Naive Bayes: utilizado quando os dados são contínuos e se assume que eles seguem uma distribuição normal. É comum em problemas de classificação de dados contínuos.
- Multinomial Naive Bayes: ideal para dados discretos, como contagem de palavras em textos. É frequentemente usado em classificação de documentos e filtragem de spam.
- Bernoulli Naive Bayes: utiliza variáveis booleanas (presença ou ausência de uma característica) e é eficaz em tarefas de classificação de texto, como análise de sentimentos.
Vantagens e desvantagens do Naive Bayes
Como qualquer modelo, o Naive Bayes possui suas limitações, que podem impactar o desempenho em determinadas situações. Abaixo, veja as principais vantagens que fazem do Naive Bayes uma escolha atrativa para muitos profissionais e as desvantagens ao implementá-lo em projetos de machine learning.
Entender esses aspectos e seu respectivo impacto no seu projeto é fundamental para aproveitar ao máximo as capacidades do algoritmo.
Vantagens do Naive Bayes
Simplicidade e eficiência
O Naive Bayes é fácil de entender e implementar, o que o torna uma excelente escolha para iniciantes em machine learning. Sua estrutura simples permite um treinamento rápido, mesmo nos casos em que há grandes conjuntos de dados.
Baixa necessidade de dados de treinamento
O algoritmo requer uma quantidade relativamente pequena de dados de treinamento para estimar os parâmetros necessários à classificação, o que é uma vantagem em cenários onde os dados são escassos.
Desempenho razoável com dados de alta dimensionalidade
O Naive Bayes é eficaz em problemas de alta dimensionalidade, como classificação de texto, onde cada palavra pode ser uma característica independente. É isso o torna ideal para tarefas como filtragem de spam e análise de sentimentos.
Escalabilidade
O modelo é altamente escalável, podendo lidar com grandes volumes de dados sem perda significativa de desempenho. A complexidade do treinamento é linear em relação ao número de variáveis, permitindo sua aplicação em situações com muitas características.
Robustez em cenários práticos
Apesar da suposição de independência condicional entre os atributos, o Naive Bayes frequentemente apresenta um desempenho satisfatório em aplicações do mundo real, superando expectativas em muitos casos.
Desvantagens do Naive Bayes
Confira quais limitações considerar ao escolher o algoritmo apropriado para o seu problema específico.
Suposição de independência
A principal limitação do Naive Bayes é a suposição de que todas as características são independentes entre si, dado o valor da classe. Essa suposição raramente é verdadeira na prática e pode levar a previsões imprecisas quando as características estão correlacionadas.
Desempenho inferior em dados correlacionados
O algoritmo pode ter um desempenho inferior em situações onde as variáveis são altamente correlacionadas, pois a independência condicional não se sustenta, afetando a precisão das previsões.
Estimativas de probabilidade
Embora o Naive Bayes possa ser eficaz em classificar corretamente as classes, ele pode falhar em fornecer boas estimativas de probabilidade para as classes, o que pode ser um problema em aplicações que dependem de probabilidades precisas.
Sensibilidade à representatividade dos dados
O desempenho do Naive Bayes pode ser afetado se os dados de treinamento não forem representativos do problema real, resultando em um modelo que não generaliza bem.
Exemplos de implementação do Naive Bayes
Exemplo de código em Python
| from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.naive_bayes import GaussianNBfrom sklearn.metrics import accuracy_score # Carregar o conjunto de dadosdata = load_iris()X = data.datay = data.target # Dividir o conjunto de dados em treino e testeX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Criar o modelo Naive Bayesmodel = GaussianNB() # Treinar o modelomodel.fit(X_train, y_train) # Fazer previsõesy_pred = model.predict(X_test) # Avaliar o modeloaccuracy = accuracy_score(y_test, y_pred)print(f”Acurácia: {accuracy:.2f}”) |
Interpretação dos resultados
A acurácia do modelo indica a proporção de previsões corretas em relação ao total de previsões feitas. Um modelo com alta acurácia é desejável, mas é bom avaliá-lo em conjunto com outras métricas, como precisão e recall.
Comparação com outros algoritmos de Machine Learning
É comum comparar o Naive Bayes com algoritmos como Decision Trees, SVM e k-NN. A escolha do Naive Bayes é válida quando a simplicidade e a rapidez são mais importantes do que a precisão máxima, especialmente em problemas de alta dimensionalidade.
Já as Decision Trees são intuitivas e oferecem uma visualização clara do processo de decisão, sendo eficazes em conjuntos de dados menores e menos complexos. Por outro lado, o SVM é conhecido por sua capacidade de lidar com espaços de alta dimensionalidade e por encontrar margens ótimas entre classes, mas pode ser computacionalmente intensivo. O k-NN, embora simples e eficaz em muitos casos, pode ser mais lento em grandes conjuntos de dados pela necessidade de calcular distâncias entre pontos.
Métricas para avaliação do Naive Bayes
O desempenho do algoritmo Naive Bayes pode ser avaliado através de várias métricas, pois cada uma oferece uma perspectiva diferente sobre a eficácia do modelo em tarefas de classificação. Confira as principais métricas abaixo.
Acurácia
A acurácia é a proporção de previsões corretas em relação ao total de previsões feitas. É uma métrica simples, mas pode ser enganosa em conjuntos de dados desbalanceados, onde uma classe pode dominar as outras.
Precisão
A precisão mede a proporção de verdadeiros positivos (TP) em relação ao total de positivos previstos (TP + Falsos Positivos – FP). Essa métrica é essencial em situações onde o custo de um falso positivo é alto, como na detecção de fraudes.
Recall
O recall, ou sensibilidade, é a proporção de verdadeiros positivos em relação ao total de positivos reais (TP + Falsos Negativos – FN). Essa métrica é importante quando é fundamental identificar todos os casos positivos, como em diagnósticos médicos.
F1-score
O F1-score é a média harmônica entre precisão e recall, oferecendo um equilíbrio entre as duas métricas. É especialmente útil em cenários com classes desbalanceadas, onde tanto a precisão quanto o recall são importantes.
Como usar a Matriz de Confusão para entender o desempenho do modelo?
A matriz de confusão é uma ferramenta valiosa para entender o desempenho do modelo. Ela apresenta um resumo das previsões do modelo em relação aos valores reais, permitindo visualizar:
- Verdadeiros Positivos (TP): casos corretamente classificados como positivos;
- Falsos Positivos (FP): casos incorretamente classificados como positivos;
- Verdadeiros Negativos (TN): casos corretamente classificados como negativos;
- Falsos Negativos (FN): casos incorretamente classificados como negativos.
A partir da matriz de confusão, dá para calcular as métricas mencionadas e entender melhor os erros do modelo, permitindo ajustes e melhorias.
Técnicas de validação cruzada
A validação cruzada é uma técnica essencial para garantir a robustez do modelo. Ela envolve dividir o conjunto de dados em várias partes, ou “folds”, e treinar o modelo várias vezes, cada vez usando um fold diferente como conjunto de teste e os demais como conjunto de treinamento. As técnicas mais comuns incluem:
- K-Fold Cross-Validation: o conjunto de dados se divide K partes e o modelo é treinado K vezes.
- Leave-One-Out Cross-Validation (LOOCV): uma forma extrema de K-Fold, onde K é igual ao número de instâncias no conjunto de dados. Cada instância é usada uma vez como conjunto de teste.
Essas técnicas ajudam a avaliar a generalização do modelo e a evitar o overfitting, proporcionando uma estimativa mais confiável do desempenho em dados não vistos.
Quer expandir seu conhecimento em Análise de Dados ou seguir na carreira de Analista de Dados? Agora, a PM3 tem a formação de Analista de Dados, um curso completo com todo o conteúdo para elevar o nível da sua profissão. Clique aqui para saber mais!





